使用Metersphere进行自动化测试和压力测试


1. 自动化测试
1.1 定义接口
手动创建
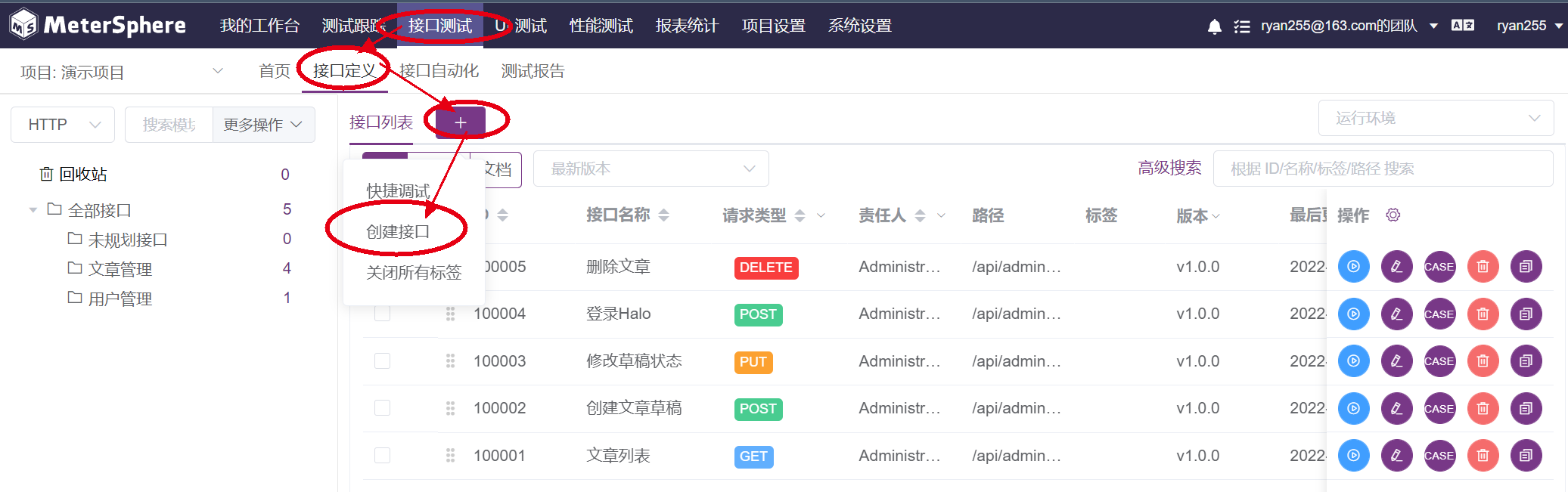
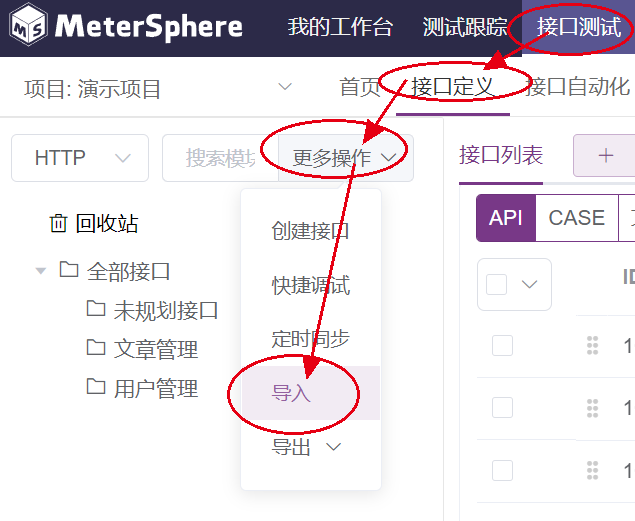
批量导入接口
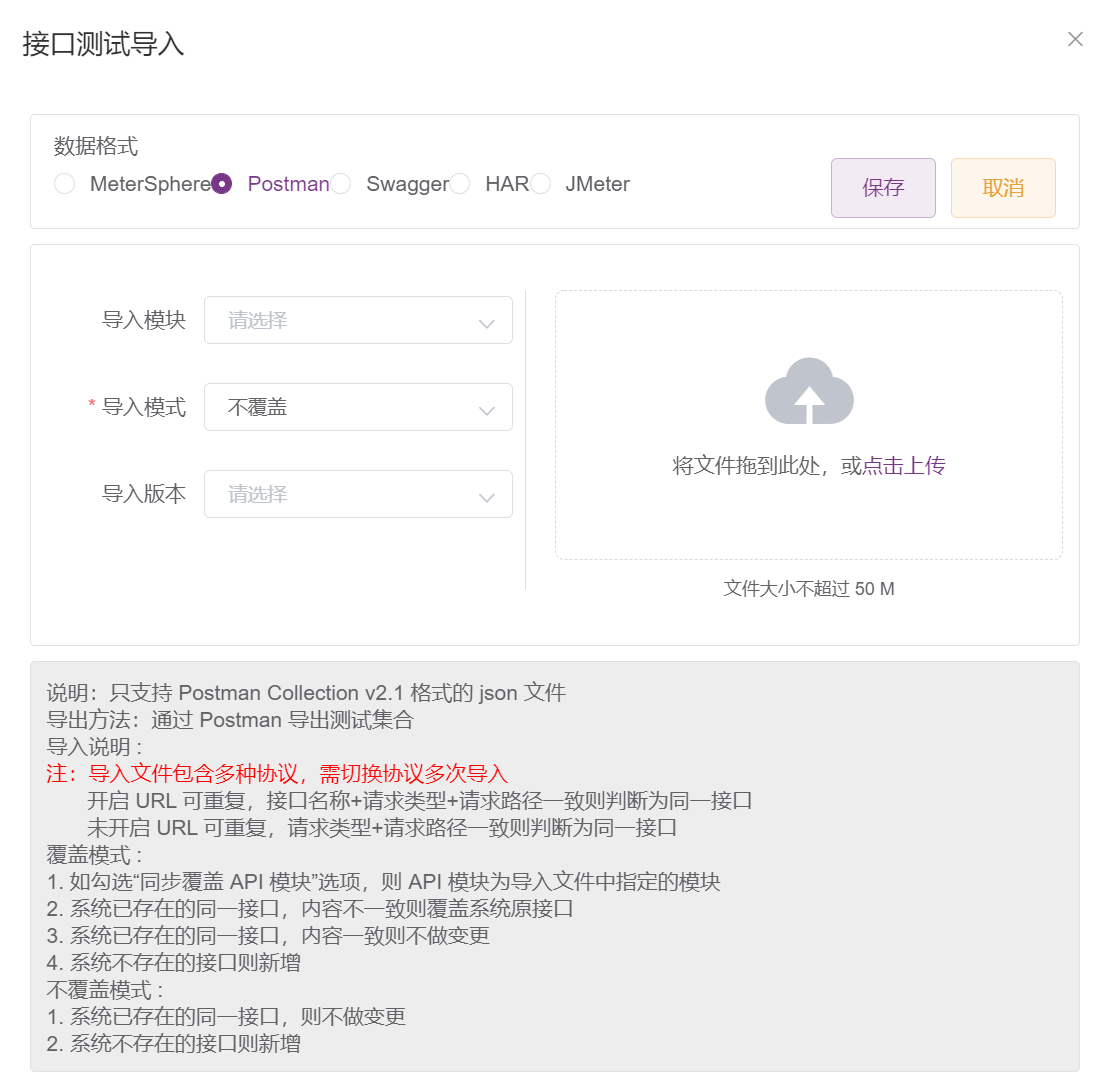
支持从postman、jmeter、swagger导入。需要主机的是,从Jmeter导入的接口不会附带断言、前置处理脚本等内容,只能导入接口本身。
1.2 环境配置
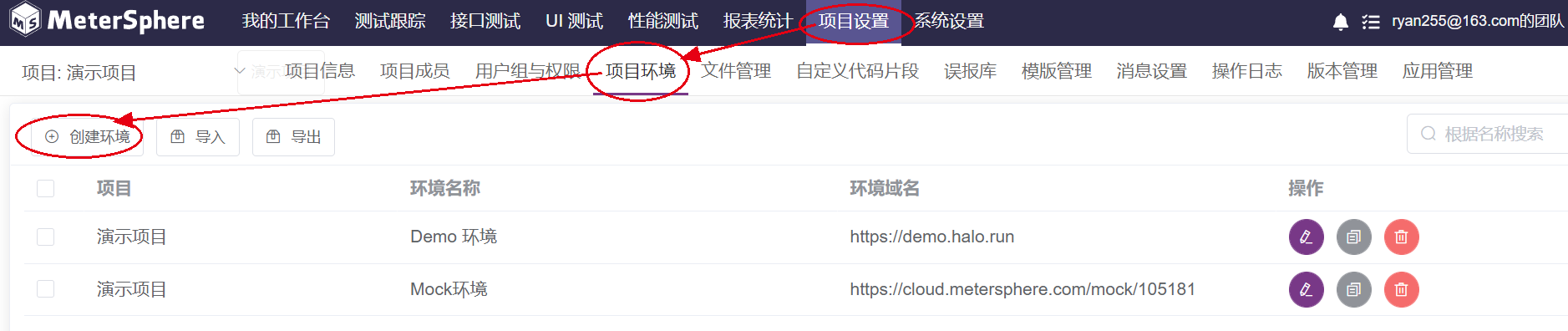
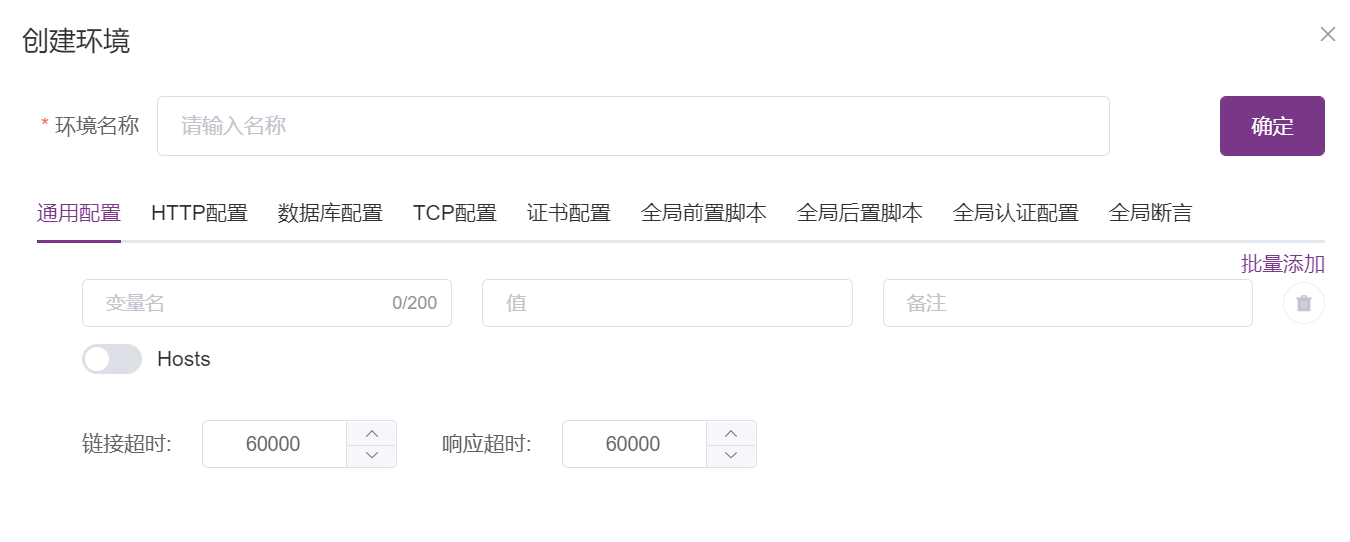
创建环境
环境属于项目的配置,所以需要在项目配置中进行配置。
主要需要配置的内容有:环境通用的变量、域名、数据库、前置后置脚本、全局断言等等
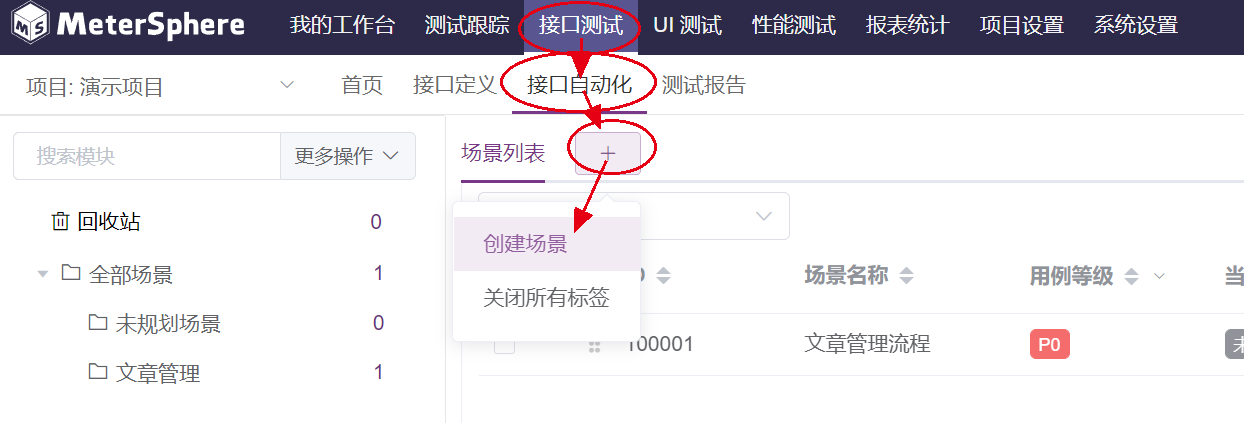
1.3 新建场景
开始分场景进行自动化测试的编写
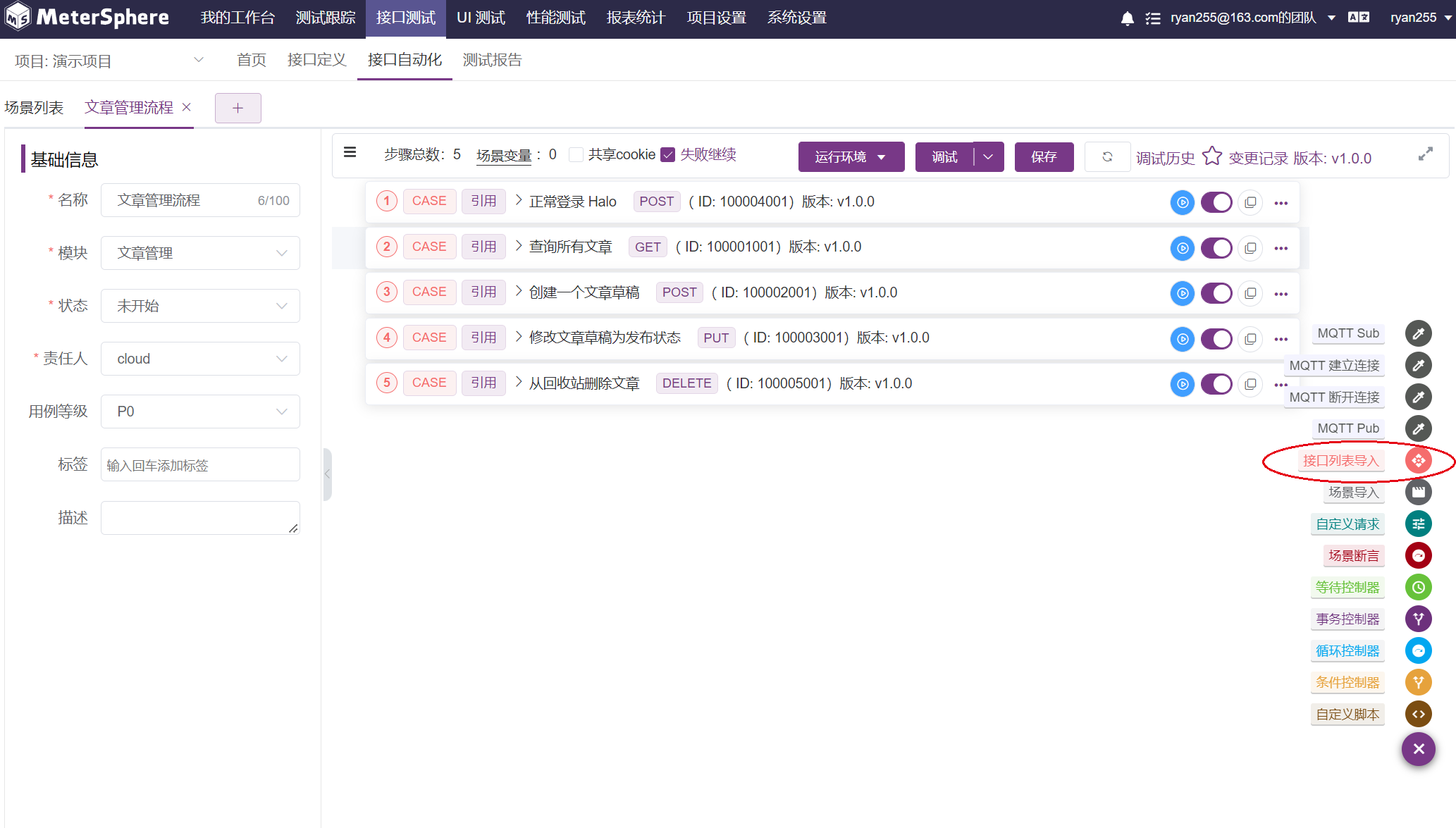
添加步骤、导入接口
点击右下角的加号 添加“步骤”
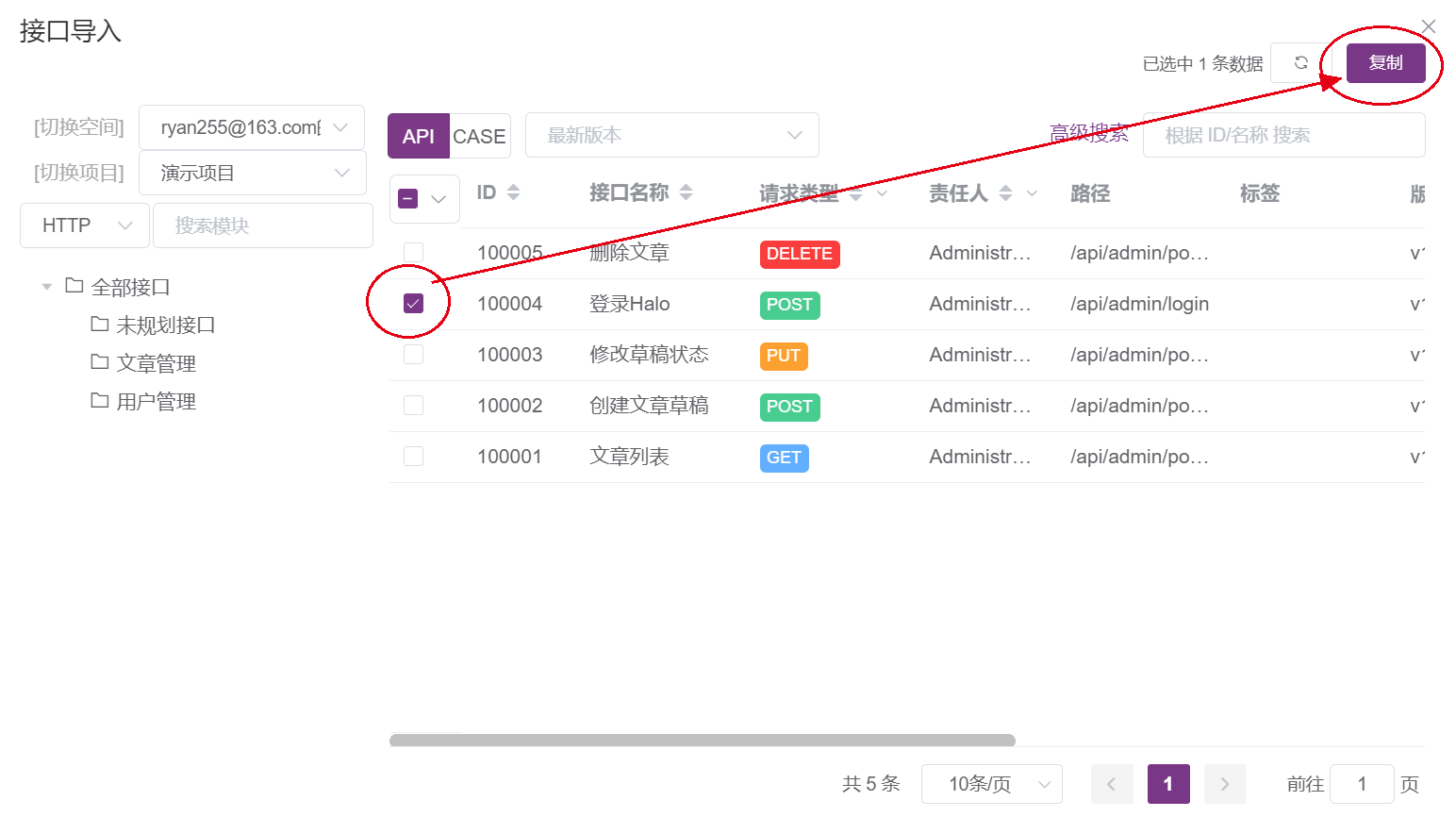
选择接口列表导入,导入之前创建的接口
设置接口前置后置处理
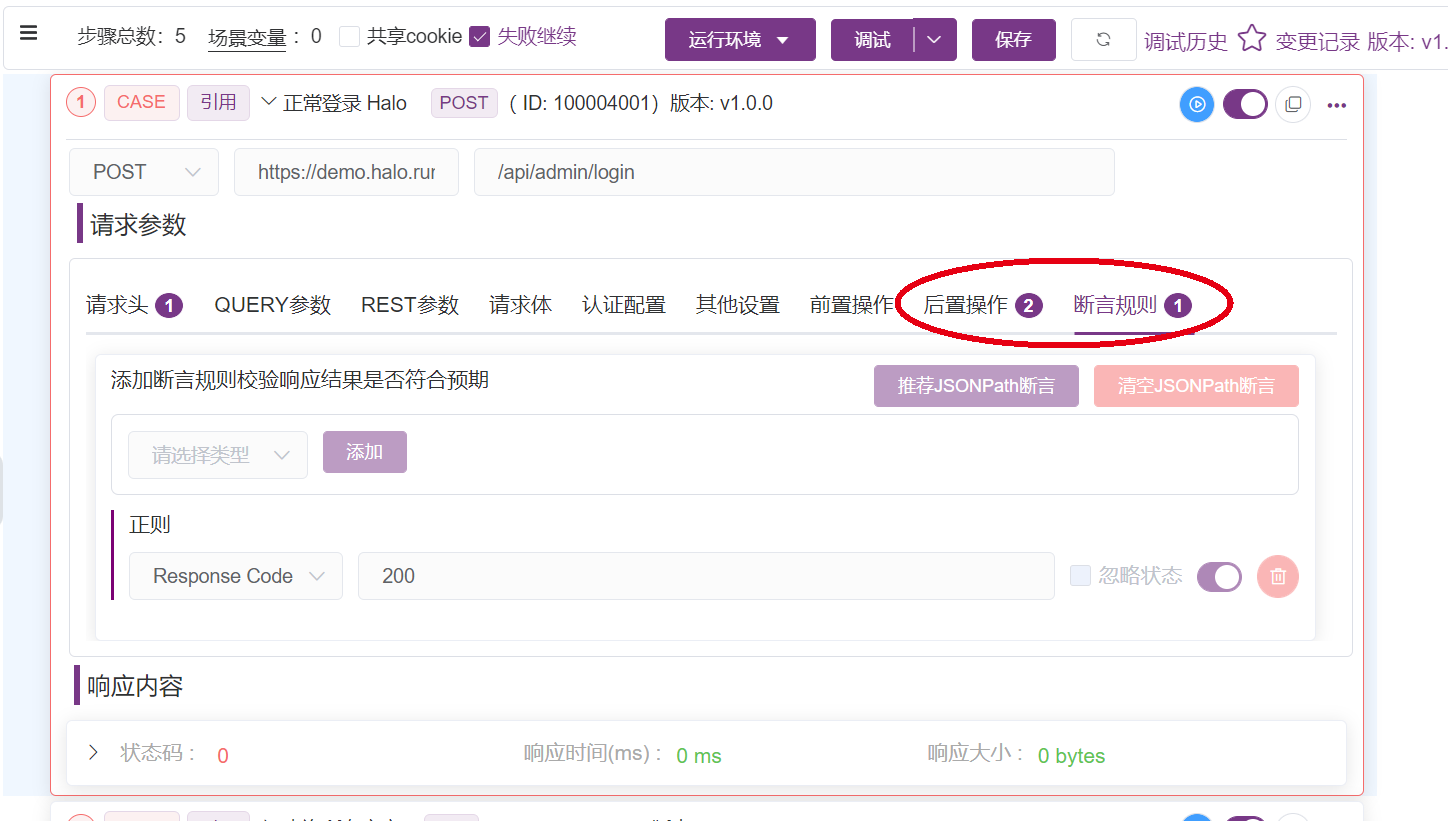
选择前置、后置脚本 点击添加
然后将之前在Jmeter写好的Beanshell后置处理器中的脚本粘贴进来
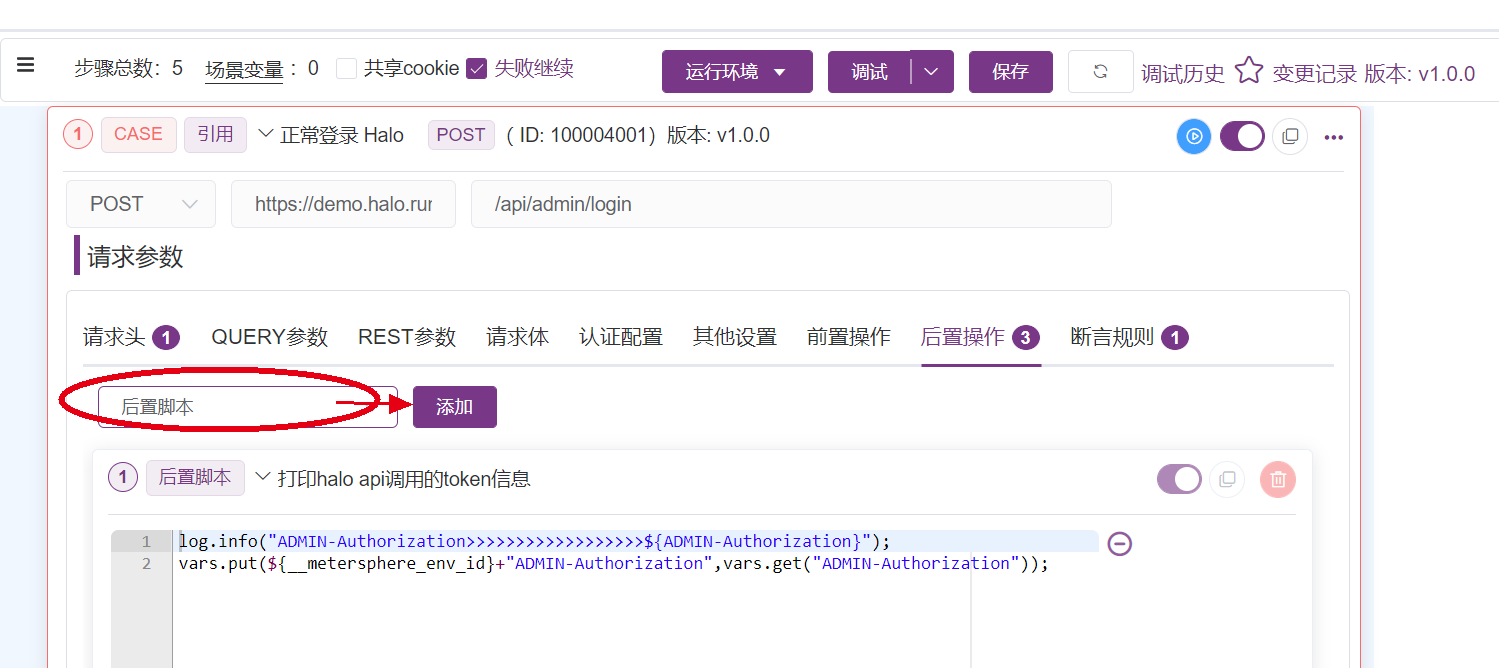
配置场景变量
将之前在Jmeter中的用户自定义变量和http请求头配置写在这里
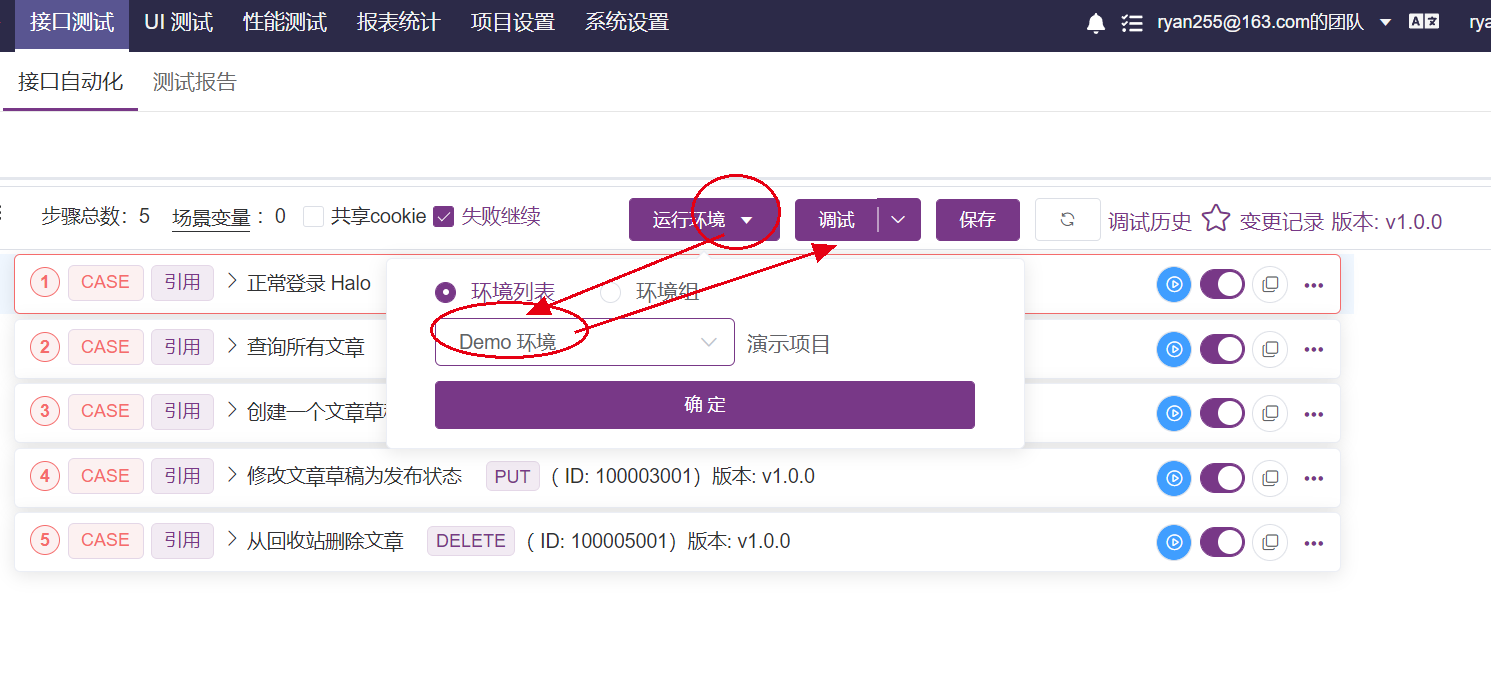
指定运行环境、执行测试
1.4 遇到的问题和解决方式
1.4.1 Metersphere无法通过sampler.getArguments()拿取get请求的入参
因为项目请求需要经过加密,而加密需要在请求前拿取请求参数,进行加密后重新给请求头中sign等字段赋值,所以需要拿取现有请求入参,并转为map以便后续处理,Jmeter Beanshell代码如下:
import org.apache.jmeter.config.Arguments;
//获取请求入参args,转为map
Arguments args = sampler.getArguments();
log.info("请求数据====" + args);
Map argsMap = args.getArgumentsAsMap();
log.info("argsMap ==============" + argsMap);
但以上代码在MeterSphere中无法拿取到get请求 (MeterSphere版本 v1.20.6-lts)(而且奇怪的是post请求的入参是可以拿取到的)
所以需要手动从url中拿取String格式的参数字段,再自己进行处理,代码如下:
String requestQuery = sampler.getUrl().getQuery();
//此处requestQuery拿取的为get请求url中?后面的内容
log.info("请求数据====" + requestQuery);
//转map
Map argsMap = new HashMap(0);
String[] params = requestQuery.split("&");
for (int i = 0; i < params.length; i++) {
String[] p = params[i].split("=");
if (p.length == 2) {
argsMap.put(p[0], p[1]);
}
}
1.4.2 前置、后置处理器中的Base64加密脚本在Metersphere中执行失败
使用MeterSphere测试平台进行自动化测试时,发现引入的一个第三方jar中的方法在执行时报错:
java.lang.NoClassDefFoundError: sun/misc/BASE64Encoder
分析之后发现 sun/misc/BASE64Encoder 这个包仅在jdk1.8以及之前的版本存在,更高版本的jdk不存在了。 而MeterSphere(1.20lts)使用的jdk版本是jdk11。
所以需要自己对引用的jar进行改造。
先用idea插件java-decompiler.jar对原有加密包tt.hlhtAes.jar进行反编译
然后自己新建项目,把反编译出的代码放进项目中进行修改:
- 添加 commons-codec 依赖
<dependency>
<groupId>commons-codec</groupId>
<artifactId>commons-codec</artifactId>
<version>1.6</version>
</dependency>
- 代码中引入
import org.apache.commons.codec.binary.Base64
-
替换原来的BASE64Encoder()
加密部分
将:BASE64Encoder base64encoder = new BASE64Encoder(); return base64encoder.encode(xxx);替换为:
Base64.encodeBase64String(xxx);解密部分
将:new BASE64Decoder().decodeBuffer(xxx);替换为:
Base64.decodeBase64(xxx);
然后重新打包即可。
不会打Jar包的点这里: JAVA-如何打包成jar包_@花花.的博客-CSDN博客_打jar包
1.4.3 拼接Bearer xxxxxxxx格式的token
JWT标准中请求头中需要加上authorization参数,该参数是由固定字符串和从上个接口返回的token字段一起拼接而成
所以在接口自动化脚本编写时,要进行字符串的拼接
- 打开jmeter上的函数助手,选择—V功能,按下图步骤输入想拼接的字段组合,点击生成:
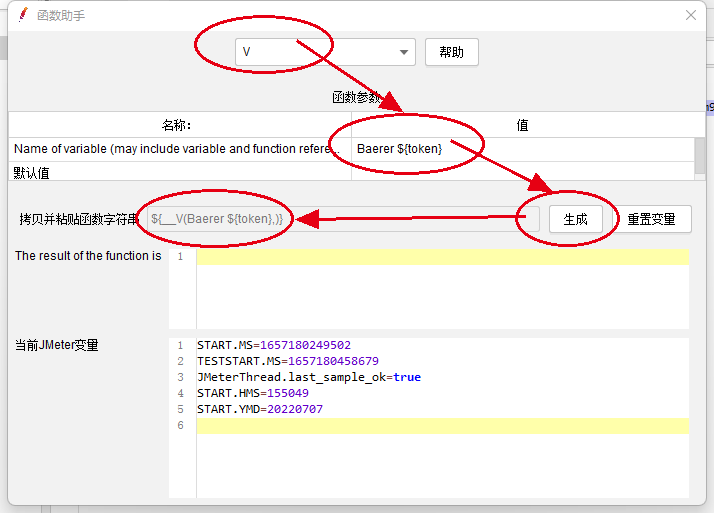
- 粘贴到使用该函数结果的位置,如无其他参数,要去掉最后面的逗号,最终结果如下:
${__V(Bearer ${token})}
2. 使用Metersphere进行压力测试
2.1 场景配置
可以引用接口自动化场景
也可以直接上传已经写好的jmx文件
2.2 压力配置
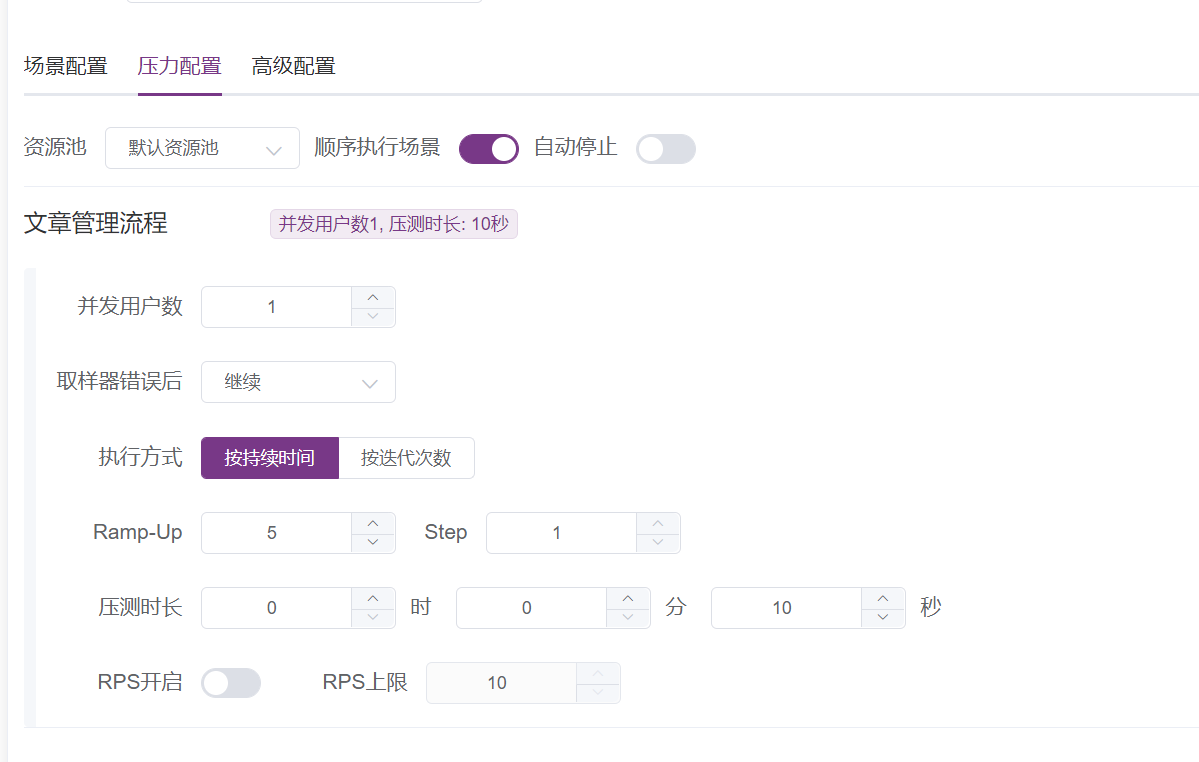
这里:
并发用户数=Jmeter中的线程数
RPS开启=Jmeter中启用Throghput Shaping Timer 但可配置的只有上限
2.3 高级配置
可以配置连接超时、响应超时的时间、自定义变量等等
最重要的高级配置是CSVDataSet。 可以通过在场景变量中上传文件的方式来进行数据驱动的压力测试,如下图所示:


2.4 CSVDataSet与线程组
讨论一下Metersphere中对CSVDataSet支持与Jmeter中的区别。
Jmeter中CSVDataSetConfig是可以设置数据文件的应用范围的,详细的情况在下方引用中。 但在Metersphere中,没有选项可以配置,默认为**”当前线程组“**。 也就是说,整个线程组读取一次文件。然后每个线程(也就是所谓每个用户)依次读取文件,即:第一个线程读取第一行数据,第二个线程读取第二行数据,以此类推。
-
全部线程
是指在CSV Data Set Config配置元件作用域范围内的所有线程共享一个数据源文件,也就是说在JMeter测试执行过程中,JMeter仅打开一次该数据源文件,每个线程读取的是同一个数据源文件中的数据.线程按照启动的先后顺序依次从数据源文件中获取一个值,不论该线程是否引用CSV Data Set Config中定义的变量,每个线程都会分配一个值,这样可以保证每个线程获取的是数据源文件中不同行的列值(在不循环取值的情况下).
-
当前线程组
是指在CSV Data Set Config配置元件作用域范围内的所有线程组,当JMeter执行测试时,每一个线程组都单独打开一次数据源文件(可以是相同或不同的数据源文件).每个线程组下的各个线程都是从数据源文件的起始处读取参数值.
若要线程组读取不同的数据源文件,可以对数据源文件的路径进行参数化.
这里需要使用{threadGroupName}来获取线程组的名字.
假设有n个线程组:tg1,tg2,…,tgn
每个线程组对应一个数据源文件,对应的文件名分别为: tg1.csv,tg2.csv,…,tgn.csv
在配置时将”Filename”设置为”…/{threadGroupName}.csv”即可. -
当前线程
在CSV Data Set Config配置元件作用域范围内的所有线程组,当JMeter执行测试时,每一个线程
都单独打开一次数据源文件(可以是相同或不同的数据源文件).
每个线程都是从数据源文件的起始处读取参数值.若要线程组读取不同的数据源文件,可以对数据源文件的路径进行参数化.
这里需要使用{threadNum}来获取线程编号.
假设有n个线程,线程编号为:1,2,…,n
每个线程对应一个数据源文件,对应的文件名分别为: testdata1.csv,testdata2.csv,…,testdatan.csv
在配置时将”Filename”设置为”…/testdata{threadNum}.csv”即可
2.5 可能遇到的瓶颈
- 网络限制:因为Metersphere服务部署在内网云,所以搞压力测试的时候,需要考虑内网访问被压服务的网络情况,内网出口带宽是否有限制。
- 服务器性能限制:压力测试在线程数量比较高、请求比较复杂数据量大的情况下,对客户端设备的性能亦有一定要求。
- 软件层面的内存限制:Metersphere的压力测试是基于Jmeter的,而Jmeter在启动时会通过配置的方式配置可以申请的最大内存,我个人本地的Jmeter是申请了较大的上限,但Metersphere如果使用默认的上限,很容易就会摸到内存瓶颈。