Run Qwen2 on Intel GPU with Text Generation WebUI
Intel Arc A770使用ipex-llm运行Qwen2大模型


本文参考:
ipex-llm项目 简单来说是一个Pytorch库,intel的CPU\iGPU\ARCGPU能够运行llm的基石 https://github.com/intel-analytics/ipex-llm
I卡上部署Text Generation WebUI官方教程(本文主要参考) https://github.com/intel-analytics/ipex-llm/blob/main/docs/mddocs/Quickstart/webui_quickstart.md#run-text-generation-webui-on-intel-gpu
Qwen2大模型 https://huggingface.co/Qwen/Qwen2-7B-Instruct
思路
- 安装ipex-llm
- 安装text-generation-webui
- 通过webui下载所需大模型并运行
1. 安装ipex-llm
参考:https://github.com/intel-analytics/ipex-llm/blob/main/docs/mddocs/Quickstart/install_windows_gpu.md
第一步,先确认显卡驱动正确安装,且驱动版本不低于31.0.101.5122。如果低于此版本,请访问
https://www.intel.com/content/www/us/en/download/785597/intel-arc-iris-xe-graphics-windows.html
下载新的驱动程序,建议下载WHQL认证的版本,相对可靠性更高。
我使用的版本: 32.0.101.5768 (WHQL Certified)
第二步,安装好python或者conda,并正确配置环境变量。建议使用conda,可以灵活配置各种虚拟环境以适应不同项目对python版本的差异性需求。官方文档里使用的Miniforge是个很优秀很轻量的conda安装器,这里同样推荐使用。
第三步,打开Miniforge Prompt
创建一个名字叫llm的python环境
conda create -n llm python=3.11 libuv
激活刚刚创建的llm环境
conda activate llm
使用pip命令安装ipex-llm
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/cn/
2. 安装text-generation-webui
第一步,点击此链接将此webui项目下载至本地并解压缩
https://github.com/intel-analytics/text-generation-webui/archive/refs/heads/ipex-llm.zip
最终路径如下(官方文档中放在了C盘,但后续下载大模型文件也在此目录下,如在C盘会过多占用系统盘空间,所以个人建议放到非系统盘下):
E:\text-generation-webui
第二步,打开Miniforge Prompt激活llm环境,进入项目目录安装依赖
conda activate llm
cd E:\text-generation-webui
pip install -r requirements_cpu_only.txt
pip install -r extensions/openai/requirements.txt
注意1:Miniforge Prompt打开后的默认路径是在C盘的User路径下,此时不能直接cd到E:\text-generation-webui,需要使用cd .. 命令逐级回到C: 根目录后,使用
E:将盘符改为E:之后再cd E:\text-generation-webui
注意2:执行两个依赖安装命令时可能会遇到权限不足的问题,此时使用管理员模式运行Miniforge Prompt,重新激活llm环境重新进入目录下执行即可
第三步,设置oneApi变量,如果是Arc独显:
set SYCL_CACHE_PERSISTENT=1
如果是核心显卡(独显用户千万别设置这个!!):
set BIGDL_LLM_XMX_DISABLED=1
第四步,启动服务
不需要API服务:
python server.py --load-in-4bit
需要API服务:
python server.py --load-in-4bit --api --api-port 5000 --listen
使用load-in-4bit选项,模型将进行优化并以 4 位精度运行。有关其他格式和精度的配置,请参阅此链接
运行完成如下图所示说明成功运行了
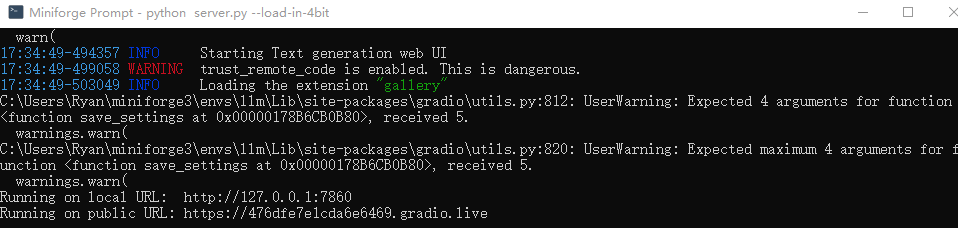
4. 使用webui安装Qwen2-7b-instruct
点击moedl标签页,在Download model or LoRA下方的输入框中填写huggingface的项目路径
Qwen/Qwen2-7B-Instruct
点击Download(页面上看不到下载进度,可以在命令行界面看)。
下载完成后,点击Model右侧的蓝色刷新按钮,然后在model下拉菜单中选择Qwen/Qwen2-7B-Instruct,选中后,将Model Loader设置为IPEX-LLM,勾选load-on-4bit选项(能有效缩减所需显存体积)
以上设置完成后,点击Load。等待加载成功后即可愉快聊天了。
注意1:load失败如果最终返回KeyError: 'qwen2',请升级transformer版本transformers>=4.37.0
pip install transformers==4.37.0(别忘了先激活llm环境哦!)
怪问题
内存溢出问题
加载模型实际上分为两步,先从硬盘读取到内存中,再从内存读取到显存中,如果内存不够大,在Load过程中就会报错,此时可以适当加大虚拟内存解决(会导致load变慢,但不影响load后的使用)
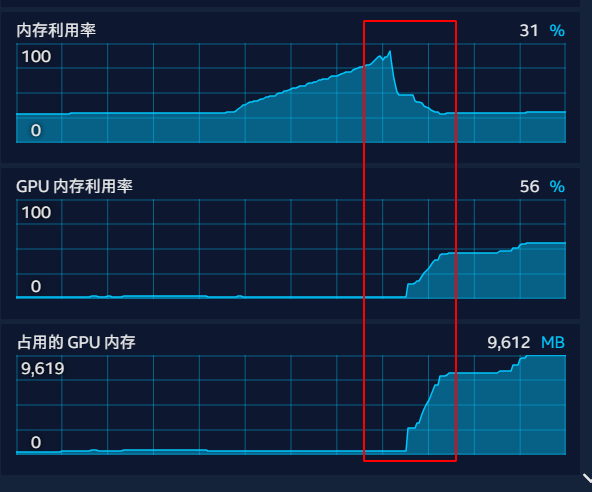
通过上图曲线可以看到,32G内存差点成为瓶颈,加载时的内存占用从30%去到了90%多,等模型弯完全加载到显存后占用才回复正常